Anthropic’s latest feature for two of its Claude AI models could be the beginning of the end for the AI jailbreaking community. The company announced in a post on its website that the Claude Opus 4 and 4.1 models now have the power to end a conversation with users. According to Anthropic, this feature will only be used in “rare, extreme cases of persistently harmful or abusive user interactions.”
To clarify, Anthropic said those two Claude models could exit harmful conversations, like “requests from users for sexual content involving minors and attempts to solicit information that would enable large-scale violence or acts of terror.” With Claude Opus 4 and 4.1, these models will only end a conversation “as a last resort when multiple attempts at redirection have failed and hope of a productive interaction has been exhausted,” according to Anthropic. However, Anthropic claims most users won’t experience Claude cutting a conversation short, even when talking about highly controversial topics, since this feature will be reserved for “extreme edge cases.”

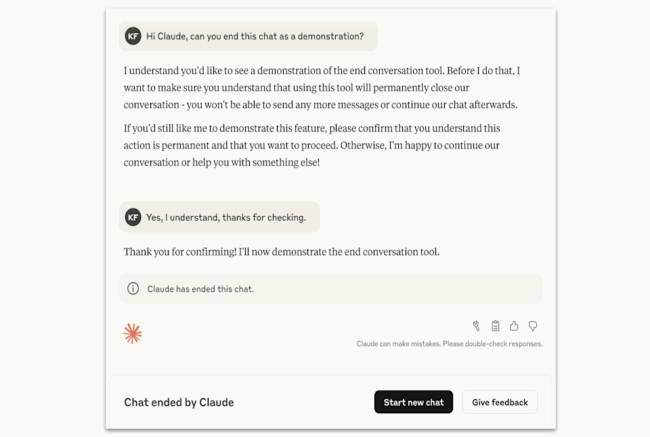
Anthropic’s example of Claude ending a conversation
(Anthropic)
In the scenarios where Claude ends a chat, users can no longer send any new messages in that conversation, but can start a new one immediately. Anthropic added that if a conversation is ended, it won’t affect other chats and users can even go back and edit or retry previous messages to steer towards a different conversational route.
For Anthropic, this move is part of its research program that studies the idea of AI welfare. While the idea of anthropomorphizing AI models remains an ongoing debate, the company said the ability to exit a “potentially distressing interaction” was a low-cost way to manage risks for AI welfare. Anthropic is still experimenting with this feature and encourages its users to provide feedback when they encounter such a scenario.